对一般的限流场景,具有两个维度的信息:
时间限流:基于某段时间范围或者某个时间点,也就是我们常说的“时间窗口”,比如对每分钟、每秒钟的时间窗口做限定
资源限流:基于可用资源的限制,比如设定最大访问次数,或最高可用连接数
分布式限流的几种维度
上面两个维度结合起来看,限流就是在某个时间窗口对资源访问做限制,比如设定每秒最多100个访问请求。但在真正的场景里,我们不止设置一种限流规则,而是会设置多个限流规则共同作用,主要的几种限流规则如下:
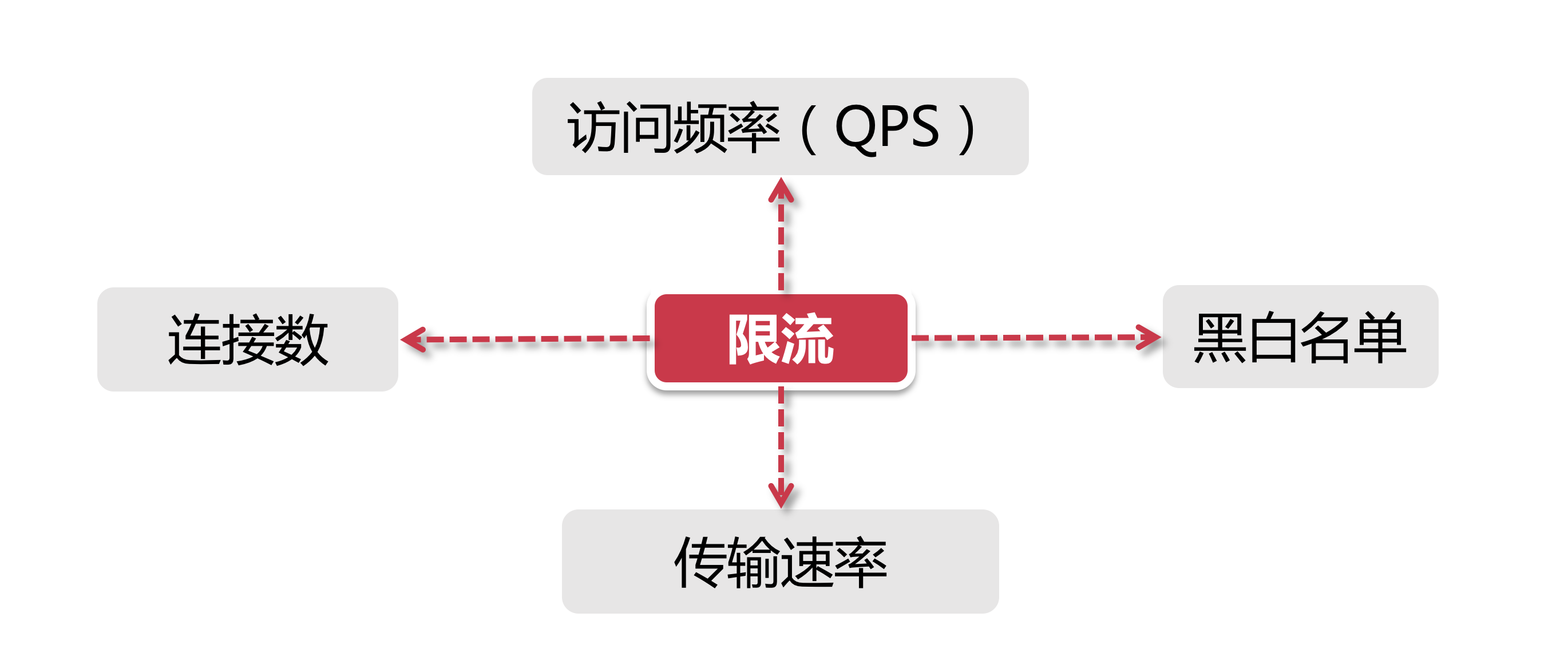
QPS和连接数控制
针对上图中的连接数和QPS(query per second)限流来说,我们可以设定IP维度的限流,也可以设置基于单个服务器的限流。
在真实环境中通常会设置多个维度的限流规则,比如设定同一个IP每秒访问频率小于10,连接数小于5,再设定每台机器QPS最高1000,连接数最大保持200。
更进一步,我们可以把某个服务器组或整个机房的服务器当做一个整体,设置更high-level的限流规则,这些所有限流规则都会共同作用于流量控制。
传输速率
对于“传输速率”大家都不会陌生,比如资源的下载速度。有的网站在这方面的限流逻辑做的更细致。
比如普通注册用户下载速度为100k/s,购买会员后是10M/s,这背后就是基于用户组或者用户标签的限流逻辑。
黑白名单
黑白名单是各个大型企业应用里很常见的限流和放行手段,而且黑白名单往往是动态变化的。
举个例子,如果某个IP在一段时间的访问次数过于频繁,被系统识别为机器人用户或流量攻击,那么这个IP就会被加入到黑名单,从而限制其对系统资源的访问,这就是我们俗称的“封IP”。
我们平时见到的爬虫程序,都必须实现更换IP的功能,以防被加入黑名单。
使用家庭宽带的同学们应该知道,大部分网络运营商都会将用户分配到不同出网IP段,或者时不时动态更换用户的IP地址。
白名单就更好理解了,可以自由穿梭在各种限流规则里,畅行无阻。
分布式环境
所谓的分布式限流,其实道理很简单,一句话就可以解释清楚。分布式区别于单机限流的场景,它把整个分布式环境中所有服务器当做一个整体来考量。
比如说针对IP的限流,我们限制了1个IP每秒最多10个访问,不管来自这个IP的请求落在了哪台机器上,只要是访问了集群中的服务节点,那么都会受到限流规则的制约。
从上面的例子不难看出,我们必须将限流信息保存在一个“中心化”的组件上,这样它就可以获取到集群中所有机器的访问状态,目前有两个比较主流的限流方案:
- 网关层限流 将限流规则应用在所有流量的入口处
- 中间件限流 将限流信息存储在分布式环境中某个中间件里(比如Redis缓存),每个组件都可以从这里获取到当前时刻的流量统计,从而决定是拒绝服务还是放行流量
小结
我们对分布式限流做了简单的了解,在实际开发中,大家需要根据自己的具体业务场景,选择合适的限流方式。
有时候,可能需要好几种限流方案相结合。
文档信息
- 本文作者:Piter Jia
- 本文链接:https://piterjia.github.io/2020/05/03/distributed-limiting/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)