为什么需要 Zookeeper
我们需要一个用起来像单机但是又比单机更可靠的东西。
举一个通俗易懂的例子
一个团队里面,需要一个leader,leader是干嘛用的?管理什么的咱不说,就说如果外面的人,想问关于这个团队的一切事情,首先就会去找这个leader,因为他知道的最多,而且他的回答最靠谱。
比如产品经理小饼过来要人,作为leader,老吕发现小耀最近没有项目安排,于是把小耀安排给了小饼的项目;
过了一会,另一个产品小西也过来要人,老吕发现刚刚把小耀安排走了,已经没人,于是就跟小西说,人都被你们产品要走了,你们产品自己去协调去。
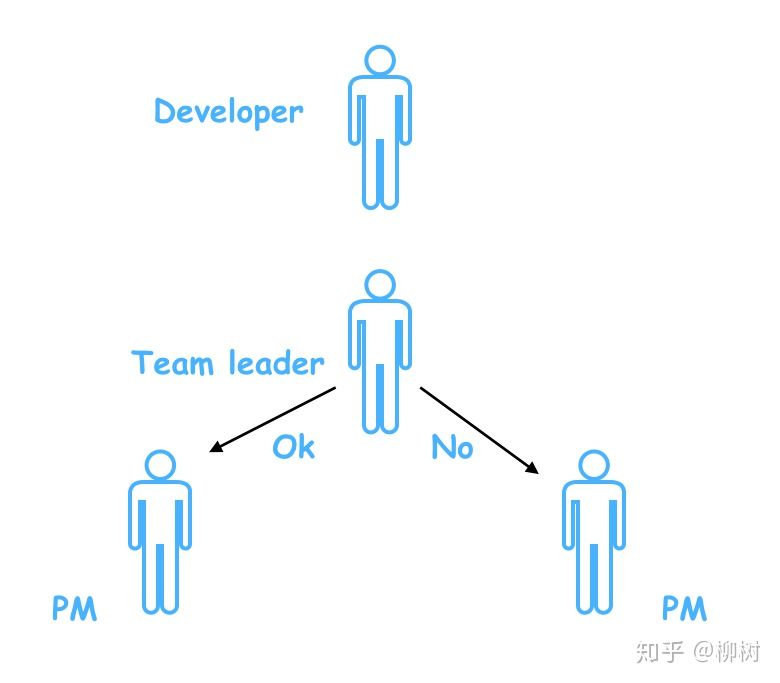
如果老吕这时候忘了小耀已经被安排走了,把小耀也分配给小西,那到时两个产品就要打架了。
这就是leader在团队里的协调作用。
同样的,在分布式系统中,也需要这样的协调者,来回答系统下各个节点的提问。
比如我们搭建了一个数据库集群,里面有一个Master,多个Slave,Master负责写,Slave只读,我们需要一个系统,来告诉客户端,哪个是Master。
有人说,很简单,我们把这个信息写到一个Java服务器的内存就好了,用一个map,key:master,value:master机器对应的ip
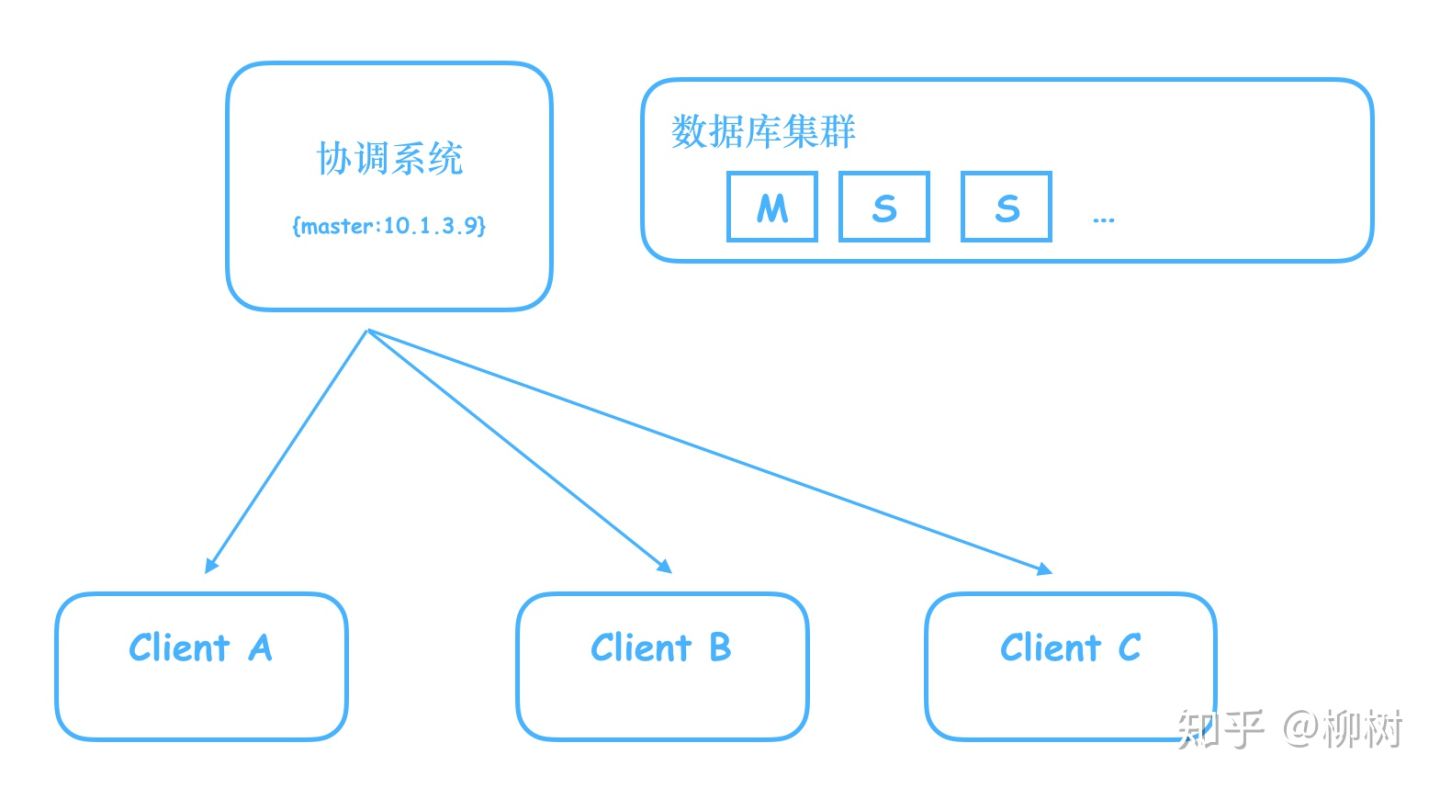
但是别忘了,这是个单机,一旦这个机器挂了,就完蛋了,客户端将无法知道到底哪个是Master。
于是开始进行拓展,拓展成三台服务器的集群。
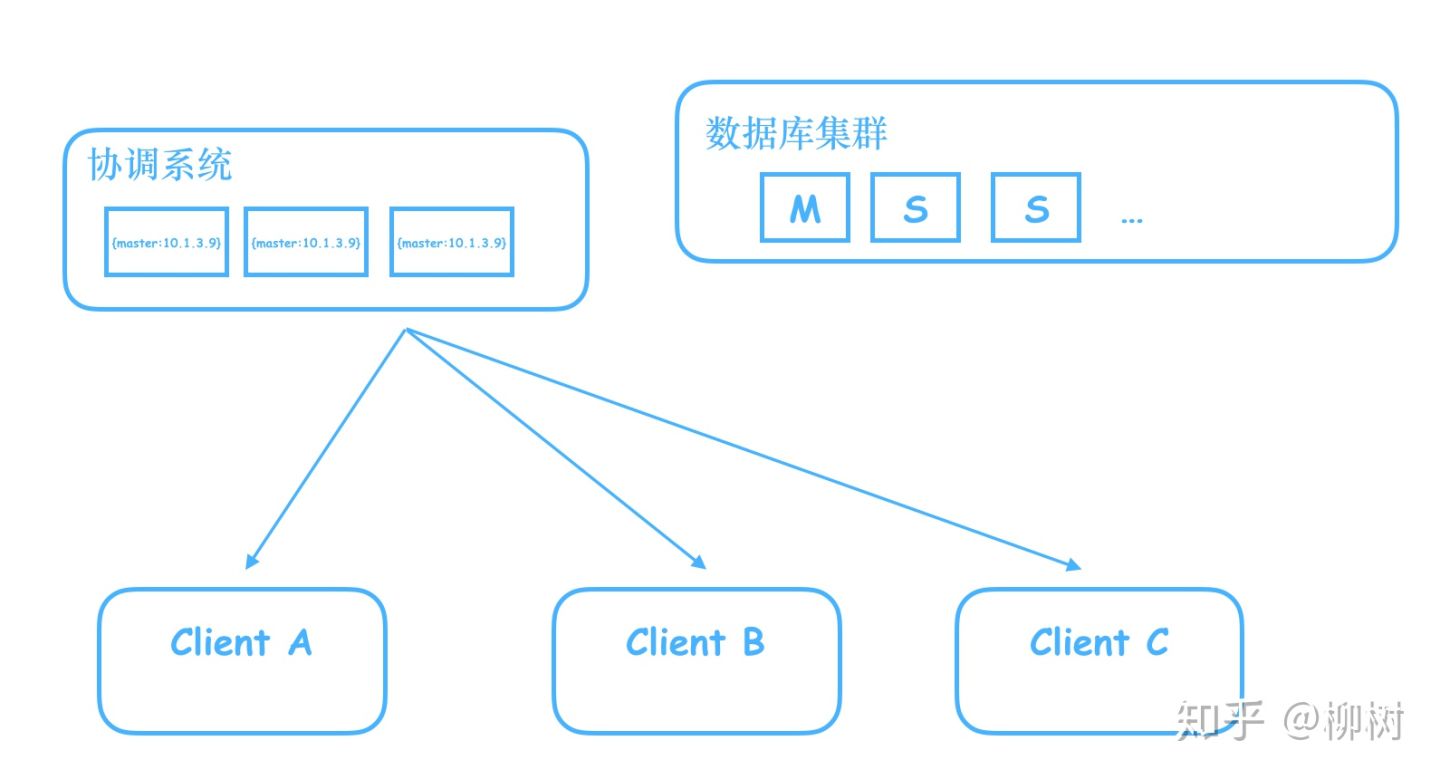
这下问题来了,如果我在其中一台机器修改了Master的ip,数据还没同步到其他两台,这时候客户端过来查询,如果查询走的是另外两台还没有同步到的机器,就会拿到旧的数据,往已经不是master的机器写数据。
所以我们需要这个存储master信息的服务器集群,做到当信息还没同步完成时,不对外提供服务,阻塞住查询请求,等待信息同步完成,再给查询请求返回信息。
这样一来,请求就会变慢,变慢的时间取决于什么时候这个集群认为数据同步完成了。
假设这个数据同步时间无限短,比如是1微妙,可以忽略不计,那么其实这个分布式系统,就和我们之前单机的系统一样,既可以保证数据的一致,又让外界感知不到请求阻塞,同时,又不会有SPOF(Single Point of Failure)的风险,即不会因为一台机器的宕机,导致整个系统不可用。
这样的系统,就叫分布式协调系统。谁能把这个数据同步的时间压缩的更短,谁的请求响应就更快,谁就更出色,Zookeeper就是其中的佼佼者。
它用起来像单机一样,能够提供数据强一致性,但是其实背后是多台机器构成的集群,不会有SPOF。
其实就是CAP理论中,满足CP,不满足A的那类分布式系统。
如果把各个节点比作各种小动物,那协调者,就是动物园管理员,这也就是Zookeeper名称的由来了,从名字就可以看出来它的雄心勃勃。
讲完了上面这些,现在再来看官网这句话,就很能理解了:
ZooKeeper: A Distributed Coordination Service for Distributed Applications
而以往的很多ZK教程,上来就是“Zookeeper是开源的分布式应用协调系统”blabla,很多像我这样的小年轻看到就会很费解,到底什么是分布式协调,为什么分布式就需要协调 …
上面只是回答了我自己提出的问题,为什么需要Zookeeper,或者说,为什么需要分布式协调系统,如果想进一步学习 ZK,你还需要了解下 Zookeeper 的内部实现原理。
比如 ZK 的宏观结构:
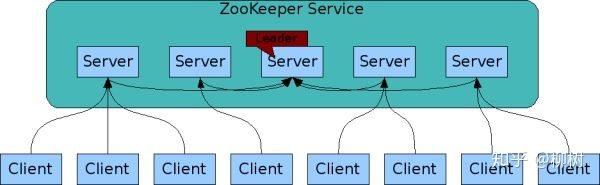
到 ZK 的微观:
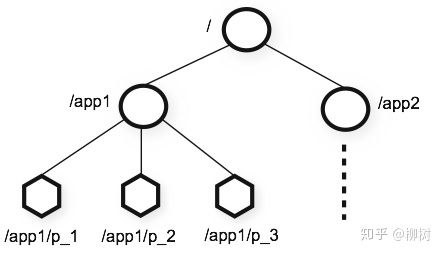
再到 ZK 是如何实现高性能的强一致的,即ZAB协议的原理,很多教程上来就开始介绍ZAB协议,很容易让人一头雾水,不知道为什么需要这样一个分布式一致性协议,有了上述介绍的背景,就好懂许多。
当然你还可以比较一下最近几年很火的 etcd 跟 ZK 的差别。
最后推荐两份 ZK 的学习资源:
ZK官网 《从 Paxos 到 Zookeeper》
文档信息
- 本文作者:Piter Jia
- 本文链接:https://piterjia.github.io/2020/03/05/why-need-zookeeper/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)